Claude Opus 4.7: Anthropics nye referansemodell — og den de holder tilbake
87,6 % på SWE-bench Verified. 70 % på CursorBench. Samme pris som 4.6. Men Anthropic innrømmer selv at Opus 4.7 ikke matcher Mythos.

Begreper i denne artikkelen
Anthropic slapp Claude Opus 4.7 den 16. april. Oppgraderingen av flaggskipmodellen bringer bedre koding, skarpere visuell forståelse, og en ny evne til å kvalitetssjekke sitt eget arbeid. Modellen er tilgjengelig nå via API, Amazon Bedrock, Google Cloud Vertex AI og Microsoft Foundry.
Det viktigste: Anthropic innrømmet åpent at Opus 4.7 ikke matcher Mythos, modellen de holder tilbake fra offentlig lansering på grunn av cybersikkerhetsbekymringer. Opus 4.7 er altså den beste modellen du kan bruke — men ikke den beste Anthropic har bygget.
Benchmark-tallene
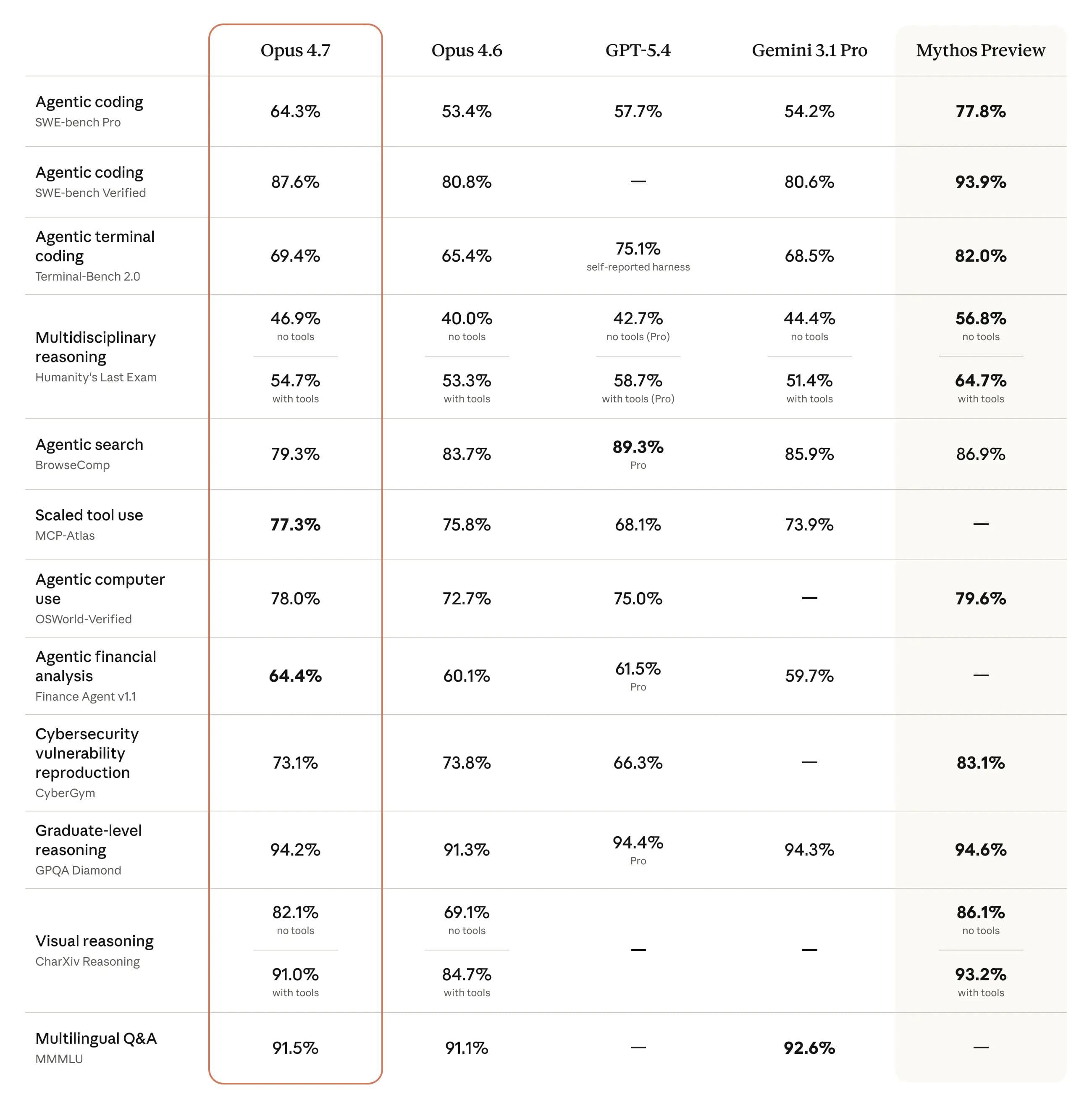
Opus 4.7 scorer 87,6 prosent på SWE-bench Verified, opp fra 80,8 prosent i Opus 4.6. Det er den høyeste publiserte scoren på denne benchmark-en per april 2026. På SWE-bench Pro, en vanskeligere variant, lander Opus 4.7 på 64,3 prosent. Opp fra 53,4 prosent, og foran GPT-5.4 på 57,7 prosent.
CursorBench, som måler autonom kodeytelse i Cursor-editoren, viser et hopp til 70 prosent fra 58 prosent. Multi-stegs agentisk resonnering er forbedret med 14 prosent, og verktøyfeil er redusert til en tredjedel.
Nye kapasiteter
Visuell forståelse: Opus 4.7 støtter bilder opptil 2 576 piksler på den lange kanten, mer enn tre ganger oppløsningsgrensen i tidligere Claude-modeller. Det betyr at skjermbilder, tekniske diagrammer og wireframes kan prosesseres i vesentlig høyere detalj — en multimodal oppgradering rettet mot utviklere og designere.
xhigh-modus: En ny innsatsnivå mellom «high» og «max» for resonnering. Gir utviklere finere kontroll over avveiningen mellom resonneringsdybde og inference-hastighet. For agent-arbeidsflyter som kjører over timer — der presisjon teller mer enn latens — er dette det mest relevante tillegget.
Selvrevisjon (/ultrareview): Opus 4.7 kan nå gjennomgå sitt eget arbeid fra forrige sesjon. Det er en funksjon som ble funnet i Claude Code-lekkasjen i mars — nå er den offisiell.
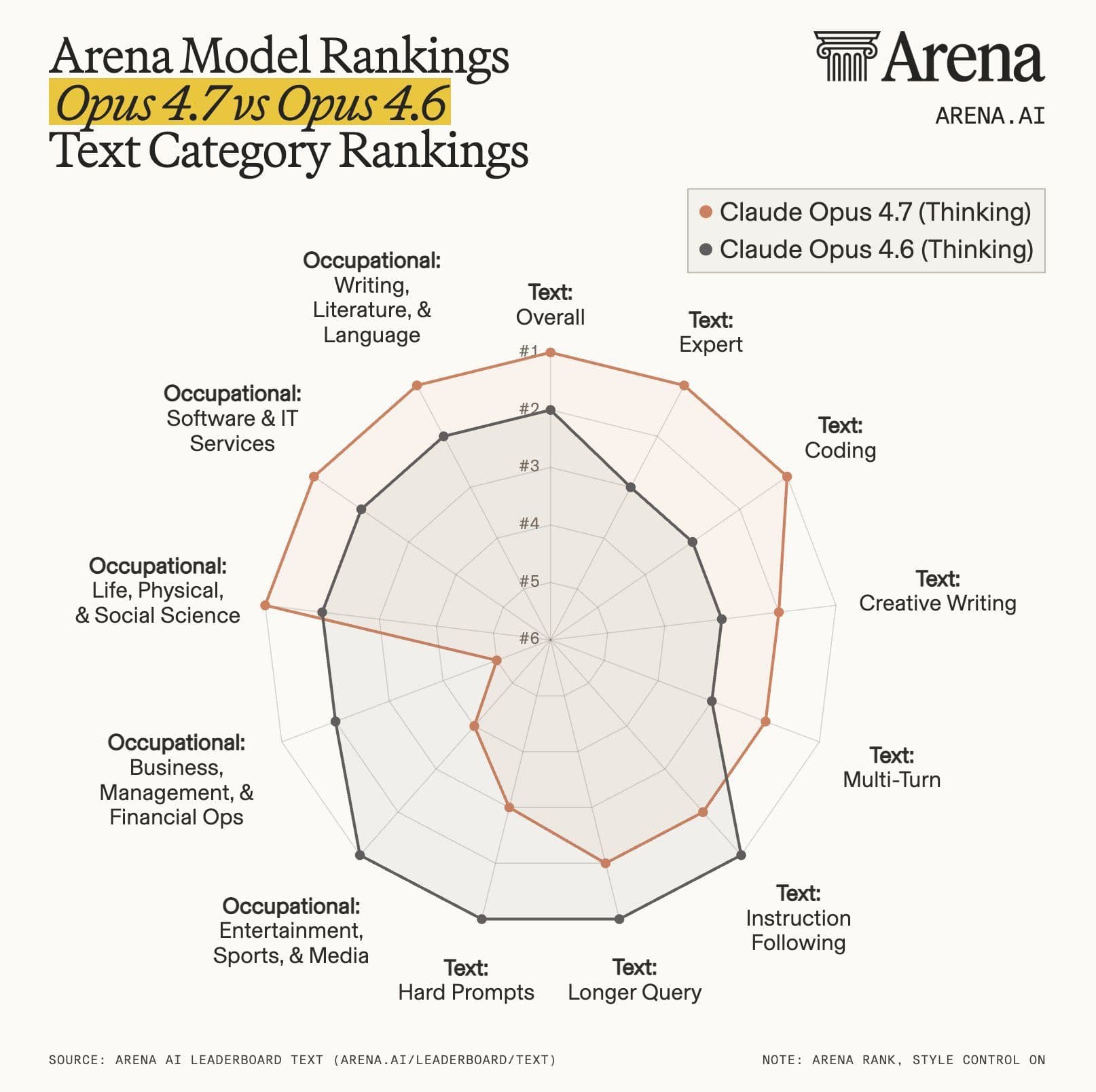
Pris og sammenligning
Prisen forblir uendret: $5 per million input-tokens og $25 per million output-tokens. Context window-et er det samme. Det betyr at oppgraderingen er ren ytelsesgevinst uten ekstra kostnad — uvanlig i en bransje der bedre modeller vanligvis betyr høyere pris.
Opus 4.7 driver nå både Claude Design (lansert 17. april) og Mythos Preview (Project Glasswing). Det plasserer modellen som Anthropics arbeidshest — kraftig nok for de fleste oppgaver, mens Mythos reserveres for cybersikkerhet.
For utviklere som allerede bruker Claude er oppgraderingen gratis og umiddelbar. SWE-bench-forbedringen fra 80,8 til 87,6 prosent er den største enkeltforbedringen mellom to Opus-versjoner, og den setter Anthropic tydelig foran GPT-5.4 og Gemini 3.1 Pro på koding.
Men Anthropics egen innrømmelse reiser et spørsmål. Hvor lenge holder en modell som referanse når selskapet som bygde den allerede har noe bedre på lager, men nekter å gi deg tilgang?


